August 24, 2020 BERT NLP Deep Learning Analytics Vidya FastAI
5 Things I Learnt After Participating in my first NLP Hackathon
Recently me and one of my friends participated as a team in a NLP Hackathon organized by Analytics Vidya. This was the first time I seriously participated in a NLP contest. It was a week long contest so we tried various techniques and made around 50-60 total submissions. In this post I discuss what I learnt by looking at the approaches of various top participants.
Problem Statement
We were given a dataset which had Titles and Abstracts from various scientific articles and the task was to predict which out of the 6 given topics, that article would belong to. Basically it was a Multi-Label Classification problem.
Results
Before sharing the mistakes that we made, I would just like to share how we performed. Just before the contest ended we were at 11th position on the public leaderboard but after the contest ended and results were evaluated on the private dataset we slipped down to 23rd position.
Learnings
After the contest ended, I was curious to explore what all techniques the top participants had used, and was even more eager to know why we slipped down 12 positions from public to private leaderboard. Below I have summarized the top 5 mistakes which I realized we had made during the contest.
1. Ignoring Imbalance in Dataset
The dataset provided to us was very imbalanced. As you can see in the image below there are 8594 articles related to Computer Science and only 249 article related to Quantitative Finance. This is a huge imbalance.
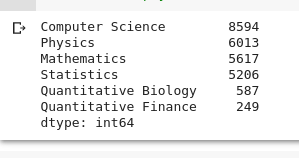
Our Approach: To resolve this we assigned weights to classes while training the models, also we tried to oversample the data using bootstrapping but it didn’t give any major boost in the results. Since we were training Transformer based models we were hopeful that it will be able to handle this on its own (but we were wrong!)
Participant’s Approach: To resolve this the top participants had used GPT and T5 models to generate new artificial samples and trained their models on that data.
2. Using Predictions from only one Model as Final Submission
This is the major reason why we slipped 12 positions from public to private.
Our Approach: During the contest we tried out 7 different models, for each model we were doing some hyper-parameter tuning and calculating the validation loss. When we felt that validation loss was lower than the previous value we made a submission and checked the score on public dataset. Our final submission was the file which scored highest on the public dataset.
Participant’s Approach: What most of the participants did was, they took the weighted average of all the submission files that they had generated from various models and then submitted it as their final submission. This helped them to make a more generalized submission, hence they didn’t see any big change in their final position.
3. Large Models does not always Guarantee better Results
A misconception that a lot of people have is that they can easily boost results by training the larger version of the model. Although this is true in most cases but in some this approach doesn’t work.
Our Approach: When we had reached the max score that we could using the base models and we were out of ideas, we thought of using the large version of the models in the hope of increasing the score. Needless to say, it didn’t improve the results.
Participant’s Approach: Most of the top participants had used the base version of the models only.
4. Using the Models Pre-Trained in that Domain
This is an interesting idea which is ofter ignored by the participants, which is, to use the models which has already been trained in the domain to which your dataset belongs to. One of the participants used the SciBERT model which has already been trained on the scientific text and was able to achieve a position in top 5.
5. Take Ideas from Similar Past Contests
Most of the participants had used ideas from a similar contest that took place on Kaggle. While we also looked in those techniques we didn’t apply all of them. So its a good idea to look at the approaches that top participants used in similar past contests.
To summarize, we were over dependent on the models to do all the work for us. We were thinking of getting good scores just by fine-tuning them, but the reality is even thought the BERT based models are very powerful, they have their limitations and you can’t just expect them to do miracles for you.
Hope you learnt something new by reading this! Hoping to get better results in upcoming contests.